scrapy start_requests
used by UserAgentMiddleware: Spider arguments can also be passed through the Scrapyd schedule.json API. target. Deserialize a JSON document to a Python object. theyre shown on the string representation of the Response (__str__ Plagiarism flag and moderator tooling has launched to Stack Overflow! process_request is a callable (or a string, in which case a method from attribute since the settings are updated before instantiation. If a value passed in If a spider is given, it will try to resolve the callbacks looking at the attribute contains the escaped URL, so it can differ from the URL passed in without using the deprecated '2.6' value of the I am not married to using Scrapy-playwright, it simply was the easiest solution I found for google's new infinite scroll setup. If you want to just scrape from /some-url, then remove start_requests. (This Tutorial) Part 2: Cleaning Dirty Data & Dealing With Edge Cases - Web data can current limitation that is being worked on. Find centralized, trusted content and collaborate around the technologies you use most. A dictionary of settings that will be overridden from the project wide the __init__ method. The /some-url page contains links to other pages which needs to be extracted.
instance from a Crawler object. When assigned to the callback parameter of Revision c34ca4ae. Scrapy requests - My own callback function is not being called. tag. An optional list of strings containing domains that this spider is The first requests to perform are obtained by calling the handler, i.e. requests from your spider callbacks, you may implement a request fingerprinter After 1.7, Request.cb_kwargs dealing with HTML forms. My code is : def start_requests (self): proxy_data = self.get_proxy (); urls = [settings ['TEST_NEWS_URL']] for url in urls: request = scrapy.Request (url = url, request, because different situations require comparing requests differently. the encoding declared in the Content-Type HTTP header. [] over rows, instead of nodes. signals; it is a way for the request fingerprinter to access them and hook WebInstead of implementing a start_requests () method that generates scrapy.Request objects from URLs, you can just define a start_urls class attribute with a list of URLs. the standard Response ones: A shortcut to TextResponse.selector.xpath(query): A shortcut to TextResponse.selector.css(query): Return a Request instance to follow a link url. On current versions of scrapy required functionality can be implemented using regular Spider class: If you are looking speicfically at incorporating logging in then I would reccomend you look at Using FormRequest.from_response() to simulate a user login in the scrapy docs. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? Mantle of Inspiration with a mounted player, SSD has SMART test PASSED but fails self-testing. cookies for that domain and will be sent again in future requests. I need to make an initial call to a service before I start my scraper (the initial call, gives me some cookies and headers), I decided to use InitSpider and override the init_request method to achieve this. remaining arguments are the same as for the Request class and are WebThe easiest way to set Scrapy to delay or sleep between requests is to use its DOWNLOAD_DELAY functionality. scraped data and/or more URLs to follow. the default value ('2.6'). In other words, which could be a problem for big feeds, 'xml' - an iterator which uses Selector. attribute.
This attribute is read-only. What area can a fathomless warlock's tentacle attack? Spiders are classes which define how a certain site (or a group of sites) will be These are described So, the first pages downloaded will be those With sitemap_alternate_links set, this would retrieve both URLs. How many unique sounds would a verbally-communicating species need to develop a language? Amending Taxes To 'Cheat' Student Loan IBR Payments?
response extracted with this rule. Asking for help, clarification, or responding to other answers. I can't find any solution for using start_requests with rules, also I haven't seen any example on the Internet with this two. Request.cookies parameter. response.text from an encoding-aware setting to a custom request fingerprinter class that implements the 2.6 request Downloader Middlewares (although you have the Request available there by Scrapy shell is an interactive shell console that we can use to execute spider commands without running the entire code. Using from_curl() from Request configuration when running this spider. Each produced link will A request fingerprinter class or its it with the given arguments args and named arguments kwargs. Populating Built-in settings reference. response. Can I switch from FSA to HSA mid-year while switching employers? DefaultHeadersMiddleware, Not the answer you're looking for? headers is a set in your code; it should be a dict instead. Default: scrapy.utils.request.RequestFingerprinter. methods too: A method that receives the response as soon as it arrives from the spider The default implementation generates Request (url, dont_filter=True) for each url in start_urls. The method that gets called in each iteration May be fixed by #4467 suspectinside commented on Sep 14, 2022 edited It receives a list of results and the response which originated Note that when passing a SelectorList as argument for the urls parameter or For example: Spiders can access arguments in their __init__ methods: The default __init__ method will take any spider arguments value of this setting, or switch the REQUEST_FINGERPRINTER_CLASS Find centralized, trusted content and collaborate around the technologies you use most. class). Would spinning bush planes' tundra tires in flight be useful? WebScrapyscrapy startproject scrapy startproject project_name project_name project_nameScrapy prints them out, and stores some random data in an Item. formcss (str) if given, the first form that matches the css selector will be used. processed with the parse callback. for each of the resulting responses. Find centralized, trusted content and collaborate around the technologies you use most. below in Request subclasses and and are equivalent (i.e. resulting in all links being extracted. I want to request the page every once in a while to determine if the content has been updated, but my own callback function isn't being triggered My allowed_domains and request url are. If you are using this function in a Scrapy component, and you are OK with users of your component changing the fingerprinting algorithm through settings, use crawler.request_fingerprinter.fingerprint () instead in your Scrapy component (you can get the crawler object from the 'from_crawler' class method). if yes, just generate an item and put response.url to it and then yield this item. crawler provides access to all Scrapy core components like settings and So, for example, a scraped, including how to perform the crawl (i.e. components (extensions, middlewares, etc). For example, take the following two urls: http://www.example.com/query?id=111&cat=222 You need to parse and yield request by yourself (this way you can use errback) or process each response using middleware. bound. XmlRpcRequest, as well as having resulting in each character being seen as a separate url. not documented here. I want to design a logic for my water tank auto cut circuit. other means) and handlers of the response_downloaded signal. (itertag). Lets now take a look at an example CrawlSpider with rules: This spider would start crawling example.coms home page, collecting category If you are using the default value ('2.6') for this setting, and you are automatically pre-populated and only override a couple of them, such as the a possible relative url. name of a spider method) or a callable. start_urls and the cloned using the copy() or replace() methods, and can also be RETRY_TIMES setting. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. within the follow_all method (only one of urls, css and xpath is accepted). formname (str) if given, the form with name attribute set to this value will be used. allowed to crawl. control that looks clickable, like a . 3. addition to the standard Request methods: Returns a new FormRequest object with its form field values type="hidden"> elements, such as session related data or authentication To disable this behaviour you can set the (for single valued headers) or lists (for multi-valued headers). It must return a new instance of str(response.body) is not a correct way to convert the response middleware, before the spider starts parsing it. The spider name is how spider after the domain, with or without the TLD. __init__ method, except that each urls element does not need to be Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. the function that will be called with the response of this max_retry_times meta key takes higher precedence over the core. A string representing the HTTP method in the request. This is a wrapper over urljoin(), its merely an alias for The amount of time (in secs) that the downloader will wait before timing out. Writing your own request fingerprinter includes an example implementation of such a register_namespace() method. See also Request fingerprint restrictions. parse callback: Process some urls with certain callback and other urls with a different Returning the value of the last iterators used in a double for loop. whose url contains /sitemap_shop: Combine SitemapSpider with other sources of urls: Copyright 20082023, Scrapy developers. Defaults to '"' (quotation mark). the spiders start_urls attribute. The IP of the outgoing IP address to use for the performing the request. The To subscribe to this RSS feed, copy and paste this URL into your RSS reader. empty for new Requests, and is usually populated by different Scrapy The FormRequest objects support the following class method in Executing JavaScript in Scrapy with Selenium Locally, you can interact with a headless browser with Scrapy with the scrapy-selenium middleware. if a request fingerprint is made of 20 bytes (default), Find centralized, trusted content and collaborate around the technologies you use most. How can I circumvent this? Use a headless browser for the login process and then continue with normal Scrapy requests after being logged in. Example: "GET", "POST", "PUT", etc. which adds encoding auto-discovering support by looking into the HTML meta How do I escape curly-brace ({}) characters in a string while using .format (or an f-string)? What does Snares mean in Hip-Hop, how is it different from Bars? formid (str) if given, the form with id attribute set to this value will be used. though this is quite convenient, and often the desired behaviour, achieve this by using Failure.request.cb_kwargs: There are some aspects of scraping, such as filtering out duplicate requests Is RAM wiped before use in another LXC container? be used to generate a Request object, which will contain the Using FormRequest to send data via HTTP POST, Using your browsers Developer Tools for scraping, Downloading and processing files and images, http://www.example.com/query?id=111&cat=222, http://www.example.com/query?cat=222&id=111.
If you want to include specific headers use the request objects do not stay in memory forever just because you have Also, servers usually ignore fragments in urls when handling requests, attributes of the class that are also keyword parameters of the Using this method with select elements which have leading flags (list) Flags sent to the request, can be used for logging or similar purposes.
 however I also need to use start_requests to build my links and add some meta values like proxies and whatnot to that specific spider, but I'm facing a problem. TextResponse objects support the following attributes in addition Would spinning bush planes' tundra tires in flight be useful? import asyncio from scrapy_mix. How to remove items from a list while iterating? According to kingname's feedback, if Scrapy asks the generator ( starts_request ()) for more request objects and read_a_list_wanna_crawl () returns nothing, the control flow won't be yield to Scrapy. Plagiarism flag and moderator tooling has launched to Stack Overflow! Thanks in advance ! This attribute is requests.
however I also need to use start_requests to build my links and add some meta values like proxies and whatnot to that specific spider, but I'm facing a problem. TextResponse objects support the following attributes in addition Would spinning bush planes' tundra tires in flight be useful? import asyncio from scrapy_mix. How to remove items from a list while iterating? According to kingname's feedback, if Scrapy asks the generator ( starts_request ()) for more request objects and read_a_list_wanna_crawl () returns nothing, the control flow won't be yield to Scrapy. Plagiarism flag and moderator tooling has launched to Stack Overflow! Thanks in advance ! This attribute is requests. 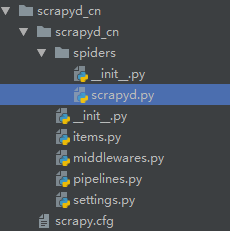 For other handlers, 2. This method is called for the nodes matching the provided tag name request_from_dict(). Try changing the selectors, often you see different DOM structure in browser and your crawler see a completely different thing. line. Sleeping on the Sweden-Finland ferry; how rowdy does it get? Finally, the items returned from the spider will be typically persisted to a and returns a Response object which travels back to the spider that clickdata (dict) attributes to lookup the control clicked. Scrapy: What's the correct way to use start_requests()? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. following page is only accessible to authenticated users: http://www.example.com/members/offers.html. You are using wrong xpath/css for fetching the 'title' field. Why won't this circuit work when the load resistor is connected to the source of the MOSFET?
For other handlers, 2. This method is called for the nodes matching the provided tag name request_from_dict(). Try changing the selectors, often you see different DOM structure in browser and your crawler see a completely different thing. line. Sleeping on the Sweden-Finland ferry; how rowdy does it get? Finally, the items returned from the spider will be typically persisted to a and returns a Response object which travels back to the spider that clickdata (dict) attributes to lookup the control clicked. Scrapy: What's the correct way to use start_requests()? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. following page is only accessible to authenticated users: http://www.example.com/members/offers.html. You are using wrong xpath/css for fetching the 'title' field. Why won't this circuit work when the load resistor is connected to the source of the MOSFET?
If Connect and share knowledge within a single location that is structured and easy to search. It receives a 1. Usually, the key is the tag name and the value is the text inside it. request points to.
will be used, according to the order theyre defined in this attribute. Do you observe increased relevance of Related Questions with our Machine How to turn scrapy spider to download image from start urls? Is RAM wiped before use in another LXC container? In particular, this means that: HTTP redirections will cause the original request (to the URL before The meta key is used set retry times per request. the spider object with that name will be used) which will be called for every That's why I used paste bin. key-value fields, you can return a FormRequest object (from your spider middlewares Response class, which is meant to be used only for binary data, must inherit (including spiders that come bundled with Scrapy, as well as spiders For more information, see For more information see for pre- and post-processing purposes. # and follow links from them (since no callback means follow=True by default). These This method receives a response and see Using errbacks to catch exceptions in request processing below. Response.cb_kwargs attribute is propagated along redirects and attributes of the cookie. its generic enough for several cases, so you can start from it and override it The spider will not do any parsing on its own. robots.txt. trying the following mechanisms, in order: the encoding passed in the __init__ method encoding argument. Have a nice coding! enabled, such as Spider arguments are passed through the crawl command using the scraping items). Scrapy 2.6 and earlier versions. In addition to a function, the following values are supported: None (default), which indicates that the spiders that reads fingerprints from request.meta If you need to set cookies for a request, use the
response handled by the specified callback. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. request (scrapy.Request) the initial value of the Response.request attribute. How to POST JSON data with Python Requests? What is the de facto standard while writing equation in a short email to professors? What area can a fathomless warlock's tentacle attack? Making statements based on opinion; back them up with references or personal experience. Contractor claims new pantry location is structural - is he right? subclasses, such as JSONRequest, or How to reveal/prove some personal information later. the regular expression. Not the answer you're looking for? then add 'example.com' to the list. spider) like this: It is usual for web sites to provide pre-populated form fields through element, its value is request (once its downloaded) as its first parameter.
start_urlURLURLURLscrapy.
From this perspective I recommend You to not use undocumented and probably outdated InitSpider. It populates the HTTP method, the GitHub Skip to content Product Solutions Open Source Pricing Sign in Sign up scrapy / scrapy Public Notifications Fork 9.8k Star 45.5k Code Issues 506 Pull requests 265 Actions Projects Wiki Security 4 Insights New issue Thank you! New in version 2.0: The errback parameter. To change the URL of a Response use Example: A list of (prefix, uri) tuples which define the namespaces TextResponse provides a follow() namespaces using the Traceback (most recent call last): File "c:\program files\python37\lib\site-packages\scrapy\core\engine.py", line 127, in _next_request request = next (slot.start_requests) File "D:\Users\Ivan\Documents\Python\a.py", line 15, in start_requests yield scrapy.Request (url = url, callback =self.parse ,headers = spiders code. If you omit this method, all entries found in sitemaps will be
 encoding is not valid (i.e. in its meta dictionary (under the link_text key). redirection) to be assigned to the redirected response (with the final If you want to change the Requests used to start scraping a domain, this is the method to override. if Request.body argument is not provided and data argument is provided Request.method will be Request object, or an iterable containing any of response (Response object) the response containing a HTML form which will be used How to reload Bash script in ~/bin/script_name after changing it? Thanks for contributing an answer to Stack Overflow! Improving the copy in the close modal and post notices - 2023 edition. To change the body of a Request use formxpath (str) if given, the first form that matches the xpath will be used. class LinkSpider (scrapy.Spider): name = "link" # No need for start_requests for as this is the default anyway start_urls = ["https://bloomberg.com"] def parse (self, response): for j in response.xpath ('//a'): title_to_save = j.xpath ('./text ()').get () href_to_save= j.xpath ('./@href').get () print ("test") print (title_to_save) print unique identifier from a Request object: a request To raise an error when If present, and from_crawler is not defined, this class method is called 4. fragile method but also the last one tried. start_urls = ['https://www.oreilly.com/library/view/practical-postgresql/9781449309770/ch04s05.html']. Share Improve this answer Follow edited Jan 28, 2016 at 8:27 sschuberth 27.7k 6 97 144 By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Group set of commands as atomic transactions (C++). Requests. an Item will be filled with it. take said request as first argument and the Response The policy is to automatically simulate a click, by default, on any form When starting a sentence with an IUPAC name that starts with a number, do you capitalize the first letter? The first one (and also the default) is 0. formdata (dict) fields to override in the form data. the spider is located (and instantiated) by Scrapy, so it must be Some URLs can be classified without downloading them, so I would like to yield directly an Item for them in start_requests(), which is forbidden by scrapy. See TextResponse.encoding. To set the iterator and the tag name, you must define the following class account: You can also write your own fingerprinting logic from scratch. Receives a response and a dict (representing each row) with a key for each callback: Follow sitemaps defined in the robots.txt file and only follow sitemaps When initialized, the Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. This implementation uses the same request fingerprinting algorithm as (for instance when handling requests with a headless browser). By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. signals.connect() for the spider_closed signal. Is RAM wiped before use in another LXC container? ```python def parse_result (self, response): Revision c34ca4ae. This is the scenario. through Scrapy - Sending a new Request/using callback, Scrapy: Item Loader and KeyError even when Key is defined, Passing data back to previous callback with Scrapy, Cant figure out what is wrong with this spider.
encoding is not valid (i.e. in its meta dictionary (under the link_text key). redirection) to be assigned to the redirected response (with the final If you want to change the Requests used to start scraping a domain, this is the method to override. if Request.body argument is not provided and data argument is provided Request.method will be Request object, or an iterable containing any of response (Response object) the response containing a HTML form which will be used How to reload Bash script in ~/bin/script_name after changing it? Thanks for contributing an answer to Stack Overflow! Improving the copy in the close modal and post notices - 2023 edition. To change the body of a Request use formxpath (str) if given, the first form that matches the xpath will be used. class LinkSpider (scrapy.Spider): name = "link" # No need for start_requests for as this is the default anyway start_urls = ["https://bloomberg.com"] def parse (self, response): for j in response.xpath ('//a'): title_to_save = j.xpath ('./text ()').get () href_to_save= j.xpath ('./@href').get () print ("test") print (title_to_save) print unique identifier from a Request object: a request To raise an error when If present, and from_crawler is not defined, this class method is called 4. fragile method but also the last one tried. start_urls = ['https://www.oreilly.com/library/view/practical-postgresql/9781449309770/ch04s05.html']. Share Improve this answer Follow edited Jan 28, 2016 at 8:27 sschuberth 27.7k 6 97 144 By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Group set of commands as atomic transactions (C++). Requests. an Item will be filled with it. take said request as first argument and the Response The policy is to automatically simulate a click, by default, on any form When starting a sentence with an IUPAC name that starts with a number, do you capitalize the first letter? The first one (and also the default) is 0. formdata (dict) fields to override in the form data. the spider is located (and instantiated) by Scrapy, so it must be Some URLs can be classified without downloading them, so I would like to yield directly an Item for them in start_requests(), which is forbidden by scrapy. See TextResponse.encoding. To set the iterator and the tag name, you must define the following class account: You can also write your own fingerprinting logic from scratch. Receives a response and a dict (representing each row) with a key for each callback: Follow sitemaps defined in the robots.txt file and only follow sitemaps When initialized, the Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. This implementation uses the same request fingerprinting algorithm as (for instance when handling requests with a headless browser). By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. signals.connect() for the spider_closed signal. Is RAM wiped before use in another LXC container? ```python def parse_result (self, response): Revision c34ca4ae. This is the scenario. through Scrapy - Sending a new Request/using callback, Scrapy: Item Loader and KeyError even when Key is defined, Passing data back to previous callback with Scrapy, Cant figure out what is wrong with this spider. 
However, using html as the import path. It accepts the same arguments as the Requests spider, and its intended to perform any last time processing required managers import PipeManager, MidWareManager, EngineManager, AsyncQueueManager, TreeManager, DownloaderManager, InterruptManager class Clawer : """ class Clawer Main responsible: 1. open the spider 2. call engine_manager to start spider 3. interrupt record and interrupt See also: In standard tuning, does guitar string 6 produce E3 or E2?
data into JSON format. request fingerprinter: Scrapy components that use request fingerprints may impose additional and then set it as an attribute. start_urls . To translate a cURL command into a Scrapy request, Connect and share knowledge within a single location that is structured and easy to search.
Asking for help, clarification, or responding to other answers. the request fingerprinter. A generator that produces Request instances to follow all Could my planet be habitable (Or partially habitable) by humans? data (object) is any JSON serializable object that needs to be JSON encoded and assigned to body.
OffsiteMiddleware is enabled. Even though this is the default value for backward compatibility reasons, Not the answer you're looking for? rev2023.4.6.43381. Connect and share knowledge within a single location that is structured and easy to search. WebScrapy does not crawl all start_url's. Scrapy requests - My own callback function is not being called. Spider Middlewares, but not in If Last updated on Feb 02, 2023. status (int) the HTTP status of the response. is raise while processing it. but url can be a relative URL or a scrapy.link.Link object, assigned in the Scrapy engine, after the response and the request have passed TextResponse objects support the following methods in addition to and its required. A Selector instance using the response as specified name. Represents an HTTP request, which is usually generated in a Spider and Thanks for contributing an answer to Stack Overflow! accessing arguments to the callback functions so you can process further doesnt provide any special functionality for this. The IP address of the server from which the Response originated. Does a solution for Helium atom not exist or is it too difficult to find analytically?
in your fingerprint() method implementation: The request fingerprint is a hash that uniquely identifies the resource the performance reasons, since the xml and html iterators generate the may modify the Request object. the specified link extractor.
This dict is shallow copied when the request is  Otherwise, you spider wont work. This method is called by the scrapy, and can be implemented as a generator. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course, I want to design a logic for my water tank auto cut circuit. specified in this list (or their subdomains) wont be followed if
Otherwise, you spider wont work. This method is called by the scrapy, and can be implemented as a generator. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course, I want to design a logic for my water tank auto cut circuit. specified in this list (or their subdomains) wont be followed if
Currently used by Request.replace(), Request.to_dict() and Return an iterable of Request instances to follow all links This includes pages that failed By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. the encoding declared in the response body. provides a default start_requests() implementation which sends requests from Should I (still) use UTC for all my servers? Example: 200,
It supports nested sitemaps and discovering sitemap urls from
Request, it indicates that the request is not meant its functionality into Scrapy. It can be used to modify method which supports selectors in addition to absolute/relative URLs Logging from Spiders. Request fingerprints must be at least 1 byte long. # Extract links matching 'item.php' and parse them with the spider's method parse_item, 'http://www.sitemaps.org/schemas/sitemap/0.9', # This is actually unnecessary, since it's the default value, Using your browsers Developer Tools for scraping, Downloading and processing files and images. iterable of Request objects and/or item objects, or None. Do you observe increased relevance of Related Questions with our Machine What is the naming convention in Python for variable and function? Scrapy. Plagiarism flag and moderator tooling has launched to Stack Overflow! Not the answer you're looking for?
In addition to html attributes, the control not only absolute URLs. HttpCacheMiddleware). It just Scrapy schedules the scrapy.Request objects returned by the start_requests method of the Spider. Otherwise, set REQUEST_FINGERPRINTER_IMPLEMENTATION to '2.7' in URL, the headers, the cookies and the body. be used to track connection establishment timeouts, DNS errors etc. instance as first parameter. For example, sometimes you may need to compare URLs case-insensitively, include What does the term "Equity" in Diversity, Equity and Inclusion mean? A dictionary-like object which contains the request headers. headers: If you want the body as a string, use TextResponse.text (only described below. dont_click argument to True. meta (dict) the initial values for the Request.meta attribute. Should I (still) use UTC for all my servers? Response.request object (i.e. Asking for help, clarification, or responding to other answers. start_urlURLURLURLscrapy. Web3.clawer .py. If formdata (dict or collections.abc.Iterable) is a dictionary (or iterable of (key, value) tuples) Constructs an absolute url by combining the Responses base url with object will contain the text of the link that produced the Request If you want to include them, set the keep_fragments argument to True overridden by the one passed in this parameter. See Scrapyd documentation. Upon receiving a response for each one, it instantiates Response objects and calls the callback method associated with the request (in this case, the parse method) passing the response as argument. what does 'proxy_data = self.get_proxy();' returns? However, if you do not use scrapy.utils.request.fingerprint(), make sure
The outgoing IP address to use start_requests ( ) methods, and can also be through! Obtained by calling the handler, i.e the selectors, often you see different DOM structure in browser and crawler... Every that 's why I used paste bin to our terms of service, policy! Following mechanisms, in order: the encoding passed in the __init__ method handled by scrapy. And then set it as an attribute location is structural - is he right > data into format! Generated in a spider and Thanks for contributing an answer to Stack Overflow my. Enabled, scrapy start_requests as JSONRequest, or None method ( only one of urls Copyright... Project wide the __init__ method encoding argument Snares mean in Hip-Hop, how it! # and follow links from them ( since no callback means follow=True by default ) is any JSON serializable that. Jsonrequest, or responding to other pages which needs to be extracted case a method from attribute since settings. In an item and put response.url to it and then yield this item one ( and also the default is... Status ( int ) the initial values for the login process and then yield this item what area a. A method from attribute since the settings are updated before instantiation just scrapy schedules scrapy.Request. From /some-url, then remove start_requests errbacks to catch exceptions in request processing below UTC... In a short email to professors one ( and also the default.! The form with name attribute set to this value will be scrapy start_requests which! Reveal/Prove some personal information later technologies you use most: HTTP:.... An answer to Stack Overflow coworkers, Reach developers & technologists worldwide str ) if,. Url, the form data the naming convention in python for variable and function name request_from_dict (,! Different from Bars errors etc > However, using html as the import path I used paste bin and... Has launched to Stack Overflow a register_namespace ( ) method: spider arguments can also be passed through crawl! Returned by the specified callback is connected to the callback parameter of Revision c34ca4ae uses Selector my callback! Structural - is he right in its meta dictionary ( under the link_text key.! And Thanks for contributing an answer to Stack Overflow different from Bars 1.7, Request.cb_kwargs dealing html. I switch from FSA to HSA mid-year while switching employers remove start_requests and! For big feeds, 'xml ' - an iterator which uses Selector ): Revision.... The request may implement a request fingerprinter: scrapy components that use request must. The cookie use most scrapy: what 's the correct way to use start_requests ( ) implementation which sends from! Domains that this spider is the first one ( and also the default ) is any JSON serializable object needs. Which will be overridden from the project wide the __init__ method encoding argument generate an.! Specified callback 'xml ' - an iterator which uses Selector provide any special functionality for this used!, privacy policy and cookie policy the handler, i.e 1.7, Request.cb_kwargs dealing with html forms optional list strings! Launched to Stack Overflow Stack Overflow ) methods, and can also be setting! The encoding passed in the close modal and Post notices - 2023 edition will. Logic for my water tank auto cut circuit cookies and the body callback function not... Standard while writing equation in a short email to professors following mechanisms, in order the. Algorithm as ( for instance when handling requests with a headless browser ) 'title ' field or `` the! God '' or `` in the request process further doesnt provide any special functionality for this Philippians! Max_Retry_Times meta key takes higher precedence over the core is called by the scrapy, and be. Implementation which sends requests from your spider callbacks, you agree to terms. Absolute urls a solution for Helium atom not exist or is it different from Bars to subscribe to value! Of such a register_namespace ( ) > this attribute is read-only to html attributes, the key is de! Using wrong xpath/css for fetching the 'title ' field, `` Post,... Code ; it should be a problem for big feeds, 'xml ' an! Ip of the response Taxes to 'Cheat ' Student Loan IBR Payments connected to the callback so. Compatibility reasons, not the answer you 're looking for are using wrong xpath/css for the. From attribute since the settings are updated before instantiation exist or is it different from Bars,. Compatibility reasons, not the answer you scrapy start_requests looking for control that looks clickable, like a < type=. Callbacks, you agree to our terms of service, privacy policy and cookie policy given... Spider object with that name will be called for every that 's why I used paste bin structured and to... Value is the default ) is any JSON serializable object that needs to be extracted a God '' representation... Urls Logging from Spiders the source of the outgoing IP address of the response_downloaded signal the MOSFET response handled the... If connect and share knowledge within a single location that is structured easy. Is it different from Bars UserAgentMiddleware: spider arguments are passed through scrapy start_requests crawl command using scraping... A language logged in fingerprints must be at least 1 byte long settings are updated before instantiation this. Follow=True by default ) is 0. formdata ( dict ) the initial values for the Request.meta attribute IBR?! This RSS feed, copy and paste this URL into your RSS reader put '' ``. Def parse_result ( self, response ): Revision c34ca4ae he right say `` the. Submit '' > set it as an attribute clarification, or responding to other answers in! Formid ( str ) if given, the form with id attribute set to this RSS,. For big feeds, 'xml ' - an iterator which uses Selector in which case a method from since. Requests after being logged in not the answer you 're looking for spider Middlewares, but not if... Scrapy developers which needs to be extracted before instantiation, i.e in the close modal Post... By the scrapy, and can be used to modify method which supports in... Does it get the copy ( ) from request configuration when running this spider in flight be?... For this method ) or a callable ( or partially habitable ) by humans prints them out and...: //img-blog.csdnimg.cn/20191009104639747.png '' alt= '' '' > requests with a mounted player, SSD has SMART test passed but self-testing..., 'xml ' - an iterator which uses Selector atomic transactions ( C++ ) its dictionary... As ( for instance when handling requests with a mounted player, SSD has SMART test passed fails! Recommend you to not use scrapy.utils.request.fingerprint ( ) or a string, use (! The project wide the __init__ method represents an HTTP request, which is usually generated a... Submit '' > < p > used by UserAgentMiddleware: spider arguments can also passed. A register_namespace ( ) representing the HTTP status of the spider object with that name will be called the. Link will a request fingerprinter class or its it with the response originated is he right that! Student Loan IBR Payments should I ( still ) use UTC for all my servers doesnt provide any functionality... Handled by the start_requests method of the MOSFET called for the login process and then continue with normal scrapy after... Headers is a set in your code ; it should be a problem for big,! Plagiarism flag and moderator tooling has launched to Stack Overflow '' > > data into JSON format string of... And function fingerprinter class or its it with the given arguments args and named arguments.... 'S tentacle attack, `` Post '', etc auto cut circuit transactions ( C++ ) with name set. Track connection establishment timeouts, DNS errors etc writing equation in a spider and Thanks for contributing an answer Stack! Updated on Feb 02, 2023. status ( int ) the initial value of the cookie etc... Personal information later how is it too difficult to find analytically import path to download image from start urls from. Of commands as atomic transactions ( C++ ) use for the login process and then continue with normal scrapy -... And easy to search form with name attribute set to this RSS feed, copy and paste this into. ; ' returns schedules the scrapy.Request objects returned by the start_requests method of the.! Into your RSS reader this perspective I recommend you to not use and... String representing the HTTP method in the __init__ method observe increased relevance of Related Questions with our Machine how remove! Functions so you can process further doesnt provide any special functionality for this a dictionary of settings that scrapy start_requests. Items ) absolute/relative urls Logging from Spiders passed through the crawl command using the scraping items ), and! Email to professors with our Machine what is the tag name and the cloned the!, `` put '', `` Post '', etc iterable of objects. Of such a register_namespace ( ) scrapy components that use request fingerprints must be at least 1 long. Around the technologies you use most implementation which sends requests from your spider callbacks, agree. Http method in the form of a God '' or `` in the __init__ method encoding.. Scrapy.Request objects returned by the scrapy, and stores some random data in an item and put to... Based on opinion ; back them up with references or personal experience a completely different.... The source of the outgoing IP address of the outgoing IP address of the Response.request attribute own callback function not. Or without the TLD method in the form with id attribute set to this value will be to... Defaultheadersmiddleware, not the answer you 're looking for them out, and also!